
Paper link | Code link | AAAI 2024
這項研究解決了與大型語言模型(LLMs)事實性評估相關的主要挑戰,並透過複雜的本體論級關係連接(ORL)機制檢測不準確性。
該框架旨在發現本體論級別的知識缺陷。
大型語言模型(LLMs)在資訊檢索方面表現出色,但經常產生不準確的回應,這個問題被稱為內在幻覺。
此問題源自於LLMs在龐大數據集上訓練時模糊且不可靠的事實分佈。
為了解決這個問題,該研究引入了 OntoFact,這是一個自適應框架,旨在通過探索知識中的本體論級別差距來檢測未知事實。
大型語言模型(LLMs)經常被批評缺乏事實準確性。
現有關於事實性檢測的研究通常採用問答方式。
文本驅動的方法使用自然語言文本來識別知識空白,以探索LLMs的局限性。
知識圖譜驅動的方法使用知識圖譜(KGs)來收集測試案例,結合實例級別的實體和關係。
然而,這兩種方法通常僅在少數典型領域的小規模數據集上進行測試。
此外,實例級別的知識圖譜包含了大量的不準確性。
本研究嘗試利用本體級別的三元組作為探測器,以提高測試案例的可靠性。
假設給定一個特定的知識圖譜 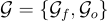 ,其中
,其中 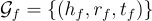 和
和 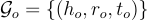 分別代表實例和本體子圖。
分別代表實例和本體子圖。
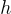 代表主體,
代表主體, 代表關係,
代表關係,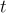 代表賓語。
代表賓語。

在第一階段,OntoFact 通過結合單個實例級別的三元組來初始化測試案例。
在第二階段,OntoFact 利用 ORL 機制在知識圖譜中沿著範圍廣泛的本體和實例遊走,自適應生成易出錯的測試案例。

最後階段,OntoFact 將測試案例輸入無幻覺檢測模塊,以獲得無偏結果。
本研究使用了三個大規模的知識圖譜:
對於大型語言模型,他們使用了20個大型語言模型。
無幻覺檢測(HFD)
他們將 錯誤比例(EP) 作為評估本體級三元組的指標。
本體驅動的強化學習(ORL)
他們使用 準確率(ACC)、精確率(P)、召回率(R) 和對應的 F1-score。
以下是該研究的實驗結果



 iThome鐵人賽
iThome鐵人賽